Storing Array in MySQL with Rust + SeaORM
Introduction
MySQL does not support arrays. You must be wondering then how it is still the most popular database that does not have a very essential type of data representation out of the box. I would argue, there are benefits to sticking to basic datatypes and allowing users to represent their data as they wish (such as an array) using constraints. I will demonstrate one such common technique here to store array data with help of Foreign Key Constraint. Usually, this representation is automatically generated in some frameworks, for example, spring boot with the ddl-auto option. However, In a rust ecosystem, things are usually verbose, requiring the programmer to know and understand the representation logic and layout of storing data in DB.
For this tutorial, I use Rust and seaorm as Object Relation Mapper. Article Assumes working knowledge of seaorm syntax (Official SeaORM tutorial).
Setup
- Clone
seaorm-mysql-array(seenoteabove) - log in to your MySQL console and create a table named
emp_db
CREATE DATABASE emp_db;
- run seaorm migrations. This will drop-create tables.
DATABASE_URL="mysql://root:password@localhost:3306/emp_db" sea-orm-cli migrate refresh
Note: Replace root and password with your credentials respectively.
now, you can run the program with cargo run. Use -- after to pass arguments to the app.
cargo run
Err! PROGRAM [show|add|rm {id}|clean]
App has the following operation:
add - Add Employee
rm {id} - Remove Employee and his projects who has {id}
clean - remove all.
show - show/find all.
An example interaction output is as follows.
Employee Name:
Jagadeesh
Employee Projects [seperated by comma(,)]:
Blog, Taxes
constructed object = EmployeeModel { id: 0, name: "Jagadeesh", projects: ["Blog", " Taxes"] }
employee Jagadeesh inserted with id = 24
project Blog inserted with id = 29
project Taxes inserted with id = 30
=== ALL DATA length=1 ===
EmployeeModel { id: 24, name: "Jagadeesh", projects: ["Blog", " Taxes"] }
=== END ALL DATA ===
refer to the source code to peek behind the curtains ;)
Storing Array Data
First, we need to define our model at the highest level, the one that we are going to use in our rust app. I defined my Employee Model as follows:
#[derive(Debug, Default)]
struct EmployeeModel {
id: i64,
name: String,
projects: Vec<String>,
}
A very simple model, with an id, name, and projects he has been assigned to.
In the earlier section, we ran migration on DB. It is nothing but creating the schema. The schema of the table Employee can be seen in migration/src/m_17012023_000001_create_employee.rs. An excerpt is given below.
1use sea_orm_migration::prelude::*;
2
3#[derive(DeriveMigrationName)]
4pub struct Migration;
5
6#[async_trait::async_trait]
7impl MigrationTrait for Migration {
8 async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> {
9 manager
10 .create_table(
11 Table::create()
12 .table(Employee::Table)
13 .col(
14 ColumnDef::new(Employee::Id)
15 .integer()
16 .not_null()
17 .auto_increment()
18 .primary_key(),
19 )
20 .col(ColumnDef::new(Employee::Name).string().not_null())
21 .to_owned(),
22 )
23 .await
24 }
25
26 async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> {
27 manager
28 .drop_table(Table::drop().table(Employee::Table).to_owned())
29 .await
30 }
31}
32
33/// Learn more at https://docs.rs/sea-query#iden
34#[derive(Iden)]
35pub enum Employee {
36 Table,
37 Id,
38 Name,
39}Similarly, We use the projects table to store multiple projects assigned to an employee.
1use super::m_17012023_000001_create_employee::Employee;
2use sea_orm_migration::prelude::*;
3
4#[derive(DeriveMigrationName)]
5pub struct Migration;
6
7#[async_trait::async_trait]
8impl MigrationTrait for Migration {
9 async fn up(&self, manager: &SchemaManager) -> Result<(), DbErr> {
10 manager
11 .create_table(
12 Table::create()
13 .table(Projects::Table)
14 .col(
15 ColumnDef::new(Projects::Id)
16 .integer()
17 .not_null()
18 .auto_increment()
19 .primary_key(),
20 )
21 .col(ColumnDef::new(Projects::EmpId).integer().not_null())
22 .foreign_key(
23 ForeignKey::create()
24 .name("fk-emp-projects")
25 .from(Projects::Table, Projects::EmpId)
26 .to(Employee::Table, Employee::Id),
27 )
28 .col(ColumnDef::new(Projects::Seq).integer().not_null())
29 .col(ColumnDef::new(Projects::Value).string().not_null())
30 .to_owned(),
31 )
32 .await
33 }
34
35 async fn down(&self, manager: &SchemaManager) -> Result<(), DbErr> {
36 manager
37 .drop_table(Table::drop().table(Projects::Table).to_owned())
38 .await
39 }
40}
41
42#[derive(Iden)]
43pub enum Projects {
44 Table,
45 Id,
46 EmpId,
47 Seq,
48 Value,
49}Points to note in the above code:
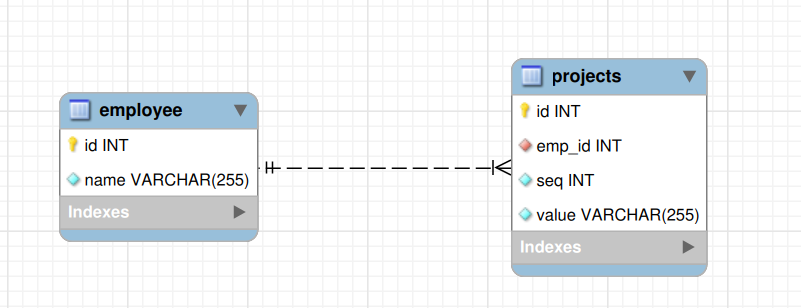
Employeehas the following columns -id,nameProjectshas the following columns:IdEmpId- Foreign KeySeq- Sequence / IndexValue
Foreign KeyRelation fromEmployee::IdtoProjects::EmpId. This Constraint makes sure that an employee cannot be deleted while corresponding projects exist, thus ensuring data integrity.
The combination of Employee and Projects tables gives us EmployeeModel that we defined in the beginning.
Inserting Employee
Take a look at the insert fn of our app.
async fn insert(emp: EmployeeModel) -> Result<(), DbErr> {
let db = get_db().await?;
let e = employee::ActiveModel {
name: ActiveValue::Set(emp.name.clone()),
..Default::default()
};
let ires = Employee::insert(e).exec(&db).await?;
println!(
"employee {} inserted with id = {}",
emp.name, ires.last_insert_id
);
for p in 0..emp.projects.len() {
let proj_name = emp.projects.clone().get(p).unwrap().to_string();
if proj_name.len() < 1 {
continue;
};
let i_proj = projects::ActiveModel {
emp_id: ActiveValue::Set(ires.last_insert_id),
seq: ActiveValue::Set(p as i32),
value: ActiveValue::Set(proj_name.clone()),
..Default::default()
};
let inserted = Projects::insert(i_proj).exec(&db).await.unwrap();
println!(
"project {} inserted with id = {}",
proj_name, inserted.last_insert_id
);
}
Ok(())
}
First, we take EmployeeModel as an argument, this is generated from user input by add_emp fn. Next, We insert e into the employee table (Needs to be converted to ActivateModel).
inserted id is stored as ires (ires.last_insert_id), This will be used as EmpId for projects related to this employee.
A range-based loop is used to insert projects into the projects table.
Removing Employee
async fn remove_emp(id: i32) -> Result<(), DbErr> {
println!("removing employee with id = {}", id);
let db = get_db().await?;
Projects::delete_many()
.filter(projects::Column::EmpId.eq(id))
.exec(&db)
.await?;
Employee::delete_by_id(id).exec(&db).await?;
Ok(())
}
Removing an employee is relatively string forward. Note that we need to remove the projects before the employee itself because of Foreign Key Relationship.
Conclusion
MySQL is the most popular DB for a lot of use cases. Though, it’s only a piece of cake if specific language tools are made to deal with complex data structures and data representations not supported by MySQL by default. If you are looking to start a project in rust and are confused as to which DB to choose, the community recommends PostgreSQL (which has native support for array).