MusicGenreClassification - Combining multiple features to make a better model
Introduction
This post is about the extension of my work in one of my projects MusicGenreClassification - a collection of methods to classify given audio clips into any of the 10 categories of GTZAN dataset that it was trained on.
Observations
in MusicGenreClassification_FeatureEnsemble.ipynb, i combined multiple features of a audio clip to make a dataset. refer to librosa documentaion for more details.
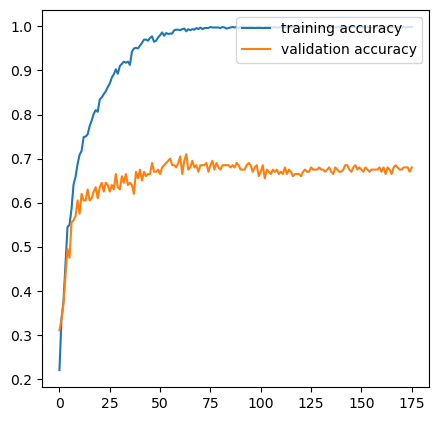
running a Dense Network on this data, this proved to be the best model giving 5-7% more accurate results compared to previous models based on MEL.the best loss achieved with this model is 0.9987499713897705
The accuracy graph of train and validation sets:
![]()